6
Idea
From a given word dictionary (containing only plain letters, i.e: no accent or other special chars), with a given fixed word length, find every same when a given number letters are missing.
For sample: un--ed could match: united, untied or unused
Using my dictionnary: /usr/share/dict/american-english, searching for same 6 letters words, having 2 letters missing let me find:
- 19242 different possible combination (shapes),
- The most matching shape is
-a-ing, that will matchsaving, gaming, hatingand more than 80 other words- There is 11209 matching shapes for which only two words match, like
-hre-dthat would only matchshrewdorthread.
The goal of this challenge is to write the most efficient algorithm (and implement them in any language) for
- extract all given fixed length words from a dictionnary
- find all possible multiple words that could be match same shape containing a given fixed number of missing letter.
- Sort and present output from the most matching shape to the less matching shape.
There are 3 variables:
- Dictionnary file name (could be STDIN)
- Fixed words length
- Number of missing chars
This could be transmitted in any way you may find usefull.
Samples
A quick sample could better explain: Searching for same shape of 18 letters, having 2 missing letters give only one match:
same /usr/share/dict/american-english 18 2
electrocardiogra--: electrocardiograms,electrocardiograph
or
same /usr/share/dict/american-english 8 2
17: --ddling: coddling,cuddling,diddling,fiddling,fuddling,huddling,meddling,middling,muddling,paddling,peddling,piddling,puddling,riddling,saddling,toddling,waddling
17: -us-iest: bushiest,cushiest,duskiest,dustiest,fussiest,fustiest,gushiest,gustiest,huskiest,lustiest,mushiest,muskiest,mussiest,mustiest,pushiest,pussiest,rustiest
16: --tching: batching,bitching,botching,catching,ditching,fetching,hatching,hitching,latching,matching,notching,patching,pitching,retching,watching,witching
15: sta--ing: stabbing,stabling,stacking,staffing,staining,stalking,stalling,stamping,standing,stapling,starling,starring,starting,starving,stashing
15: --ttered: battered,bettered,buttered,fettered,guttered,lettered,littered,mattered,muttered,pattered,pottered,puttered,tattered,tittered,tottered
...
2: -e-onate: detonate,resonate
2: c-mmune-: communed,communes
2: trou-le-: troubled,troubles
2: l-t-rals: laterals,literals
2: sp-ci-us: spacious,specious
2: -oardi-g: boarding,hoarding
2: pre-ide-: presided,presides
2: blen-he-: blenched,blenches
2: sw-llin-: swelling,swilling
2: p-uc-ing: plucking,pouching
or
The shape
---l-matchhelloandworldas well as 297 other words.:same /usr/share/dict/american-english 5 4 | sed -ne '/hello/{s/^ *\([0-9]*: [a-z-]*\):.*,world,.*$/\1/p}' 299: ---l-
Test file
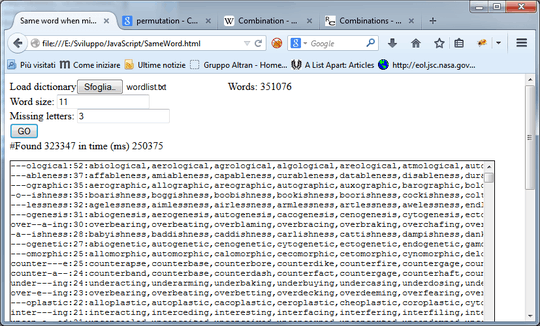
For testing, I've posted this 62861 length extract from my dict file in plain ascii, useable from jsfiddle, jsbin or even from your filesystem (because of the directive access-control-allow-origin) ( sample: @edc65 answer, with score count ).
Ranking
This is a fastest algorithm challenge.
The goal of this is to find quickest way for building shape, making comparissions and sorting list.
But the natural speed of language have to not be matter. So if a solution using bash is slower, but simplier, using more efficient algorithm than another c based solution, the simplier (maybe slower) have to win.
The score is the number of logical steps required by the whole job, using any dictionary file (my personal english dictionary: wc -l /usr/share/dict/american-english -> 99171) and different combinations of word length and number of missing letters.
The lowest score win.

F. Hauri
Posted 2014-08-02T17:11:09.230
Reputation: 2 654

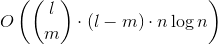

 Problems (for javascript version)
Problems (for javascript version)




It looks like you're mixing up the winning criteria a bit here. First you say "most efficient", then you say it's a code-challenge. But then you say scoring is by upvotes, which would mean popularity-contest. Also, you're using the fastest-code tag which is for runtime as opposed to the fastest-algorithm tag for computational complexity. I'm confused. – Martin Ender – 2014-08-02T17:32:52.130
@MartinBüttner You're right, I was not so clear... I hope this is better now. – F. Hauri – 2014-08-02T18:55:33.830
I see... scoring by computational complexity isn't a new thing here though, and I think with the help of the community it should be possible to figure it out for most algorithms. I wouldn't side step this by scoring by votes, because you can't control people to vote by efficiency either. This sounds like a decent challenge for a plain fastest-algorithm scoring. – Martin Ender – 2014-08-02T19:03:50.627
@MartinBüttner Ok this would implie a consistent work for evaluating answer, but it's the goal anyway. – F. Hauri – 2014-08-02T19:31:50.970
based on the samples given, it looks like you already have a solution. would you submit it? – Sparr – 2014-08-02T20:15:06.333
My test command:
cat <(time tee >(wc -l) >(sed -ne '1,3{s/^\(.\{'$[COLUMNS-4]'\}\).*$/\1.../;p};4s/^.*$/.../p;5{N;N;:a;$!N;$!{ s/^[^\n]*\n//;ta};};$p;') >/dev/null < <(./same_missing-X.py /usr/share/dict/american-english 4 2 ))Doing so permit quick change of parameters for another run :-) – F. Hauri – 2014-08-02T23:36:17.017Can someone give the url of a suitable dictionary? I have this one used in another challenge but is quite big. https://github.com/noirotm/lingo/blob/master/wordlist.txt
– edc65 – 2014-08-03T06:39:26.760Yes, this is big, but correct. @edc65 the file you use is fine. Ok you could drop some line for test:
sed -ne '/^[a-z]\{2,15\}$/{p;N;N;N;N;d}' <wordlist.txt >wordlist-test.txt, with more or less;Nfor making smaller or bigger file. – F. Hauri – 2014-08-03T07:57:08.460Playing with my solution, I found that many words repeat a lot, like:
accen-e-:2:accensed,accented accen--d:2:accensed,accented acce-s-d:2:accensed,accessed ac-en-ed:2:accensed,accented a-cen-ed:2:accensed,accented -ccen-ed:2:accensed,accented... and counting. Is that correct and expected? – edc65 – 2014-08-03T10:31:58.697@edc65 Yes. the job is purely mechanical... Even where only 1 letter differ, this could match 2 missing letters mask... – F. Hauri – 2014-08-03T19:31:01.560