23
4
Your task is to read an image containing a handwritten digit, recognize and print out the digit.
Input: A 28*28 grayscale image, given as a sequence of 784 plain-text numbers from 0 to 255, separated by space. 0 means white and 255 means black.
Output: The recognized digit.
Scoring: I will test your program with 1000 of the images from the MNIST database training set (converted to ASCII form). I have already selected the images (randomly), but will not publish the list. The test must finish within 1 hour, and will determine n - the number of correct answers.
n must be at least 200 for your program to qualify. If the size of your source code is s, then your score will be calculated as s * (1200 - n) / 1000. Lowest score wins.
Rules:
- Your program must read the image from the standard input and write the digit to the standard output
- No built-in OCR function
- No third-party libraries
- No external resources (files, programs, web sites)
- Your program must be runnable in Linux using freely available software (Wine is acceptable if necessary)
- The source code must use only ASCII characters
- Please post your estimated score and a unique version number every time you modify your answer
Example input:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
By the way, if you prepend this line to the input:
P2 28 28 255
you will obtain a valid image file in pgm format, with inverted/negated colors.
This is what it looks like with correct colors: 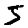
Example output:
5
Standings:
No.| Name | Language | Alg | Ver | n | s | Score
----------------------------------------------------------------
1 | Peter Taylor | GolfScript | 6D | v2 | 567 | 101 | 63.933
2 | Peter Taylor | GolfScript | 3x3 | v1 | 414 | 207 | 162.702

aditsu quit because SE is EVIL
Posted 2014-05-19T03:33:44.340
Reputation: 22 326

Related, but not quite the same (not a challenge, but very useful for finding the latex codes): http://detexify.kirelabs.org/classify.html . It also recognizes numbers.
– Justin – 2014-05-19T05:37:23.4431Can we safely assume that we only need to consider the black pixels? The >127 pixels? What can we assume? – Justin – 2014-05-19T05:41:20.153
@Quincunx I can't get it to recognize 4. And I'm not sure about your question, but you can check some samples from the training set. – aditsu quit because SE is EVIL – 2014-05-19T05:41:22.417
That's because Latex is too complex. It gets
\Jupiterthough (which looks remarkably similar) – Justin – 2014-05-19T05:42:13.4902Especially if this is a code golf question, please constrain to black and white input. People make their entire careers out of solving this problem without having to count characters in their code. Not publishing which characters you've picked is a way of stopping cheating, and makes it sort of a gamble... and given that it's unreasonable for people to be writing AI here, the fun is doing some weird heuristic and then seeing how well it does in the tournament vs. competition. – HostileFork says dont trust SE – 2014-05-19T05:55:36.927
@Dr.Rebmu if you really need black and white, you are free to convert the image. People maybe used to make careers out of this 50 years ago, but nowadays it's a basic task for a machine-learning student. Oh, you wrote it's unreasonable to write AI here? I think if you use a suitable language, coughoctavecough, it's perfectly reasonable. – aditsu quit because SE is EVIL – 2014-05-19T06:03:23.503
3@aditsu Yes, anyone can do it poorly. But you're not asking for it to be done poorly, you want someone to "win" in a competition, where the character count is measured. I think paring the problem down a bit is more realistic for hobbyist puzzle solvers. Constraining the input seems a good start on making it reasonable. I'd suggest a pre-pass on the input to say that it's black and white. – HostileFork says dont trust SE – 2014-05-19T06:06:51.997
@Dr.Rebmu Well, a 20% success rate is very poor, but would be enough to qualify, and possibly win if nobody else can do better. Or if the better program is MUCH longer. – aditsu quit because SE is EVIL – 2014-05-19T06:09:06.880
It seems there are two main hard parts of OCR: figuring out which pixels are part of the character and determining from the shape which character it is. I recommend you emphasize only the second part as @Dr.Rebmu recommends. – Justin – 2014-05-19T06:10:10.847
Also: what is the winning criterion? Is it number of characters, or accuracy against your undisclosed test data? (Please note: I'm not trying to be mean...I got a surprising beat-down on my Beast puzzle which I thought was simple, but turned out to have lots of edge cases that caught me by surprise...)
– HostileFork says dont trust SE – 2014-05-19T06:28:57.640@Dr.Rebmu, the scoring system is specified. It's a mixture of accuracy and code length, but with sufficient weight on accuracy that [tag:code-challenge] is more appropriate than [tag:code-golf]. – Peter Taylor – 2014-05-19T08:23:58.363
2@Dr.Rebmu and anybody else who wants black and white input: feel free to convert the input using a threshold such as 128. I checked and the digits are still recognizable (by my brain). You can try other thresholds too, they may give better results. – aditsu quit because SE is EVIL – 2014-05-19T09:55:41.987
For the record, I wrote a pretty dumb solution in python and obtained a score of 1157 – aditsu quit because SE is EVIL – 2014-05-19T12:32:46.600
I wrote a script that just prints
.when >0 (and also for >200 just to see the difference) & space otherwise; and I must say, your test case doesn't really look like a5to me. – Kyle Kanos – 2014-05-19T12:44:53.170@KyleKanos check the image I added – aditsu quit because SE is EVIL – 2014-05-19T12:53:13.230
Okay, that looks a lot more like a 5 than my output (which is my terminal so it isn't really a square & skewed my image). That weird hook hanging down on the top bar is what really threw me off. – Kyle Kanos – 2014-05-19T12:56:52.330