16
2
Background
Perfect shuffle algorithms like Fisher-Yates shuffle don't produce great results when it comes to music playlist shuffling, because it often produces clusters of songs from the same album. In an attempt to solve this problem, Spotify introduced an interesting shuffle algorithm in 2014. At the end of the article, they claimed (emphasis mine):
All in all the algorithm is very simple and it can be implemented in just a couple of lines. It’s also very fast and produces decent results.
Let's see if this is indeed the case.
Task
Implement the modified Spotify shuffle. The algorithm described in the article has some gaps in its specification, so I present a refined one here.
The algorithm
Let's assume we have a list of items grouped into categories, e.g.:
[['A', 'AA', 'AAA'], ['B'], ['C', 'CC'], ['D'], ['E', 'EE', 'EEE', 'EEEE']]
Shuffle items within each category.
- You may use any shuffle algorithm that can produce every possible permutation with nonzero probability.
[['AAA', 'A', 'AA'], ['B'], ['C', 'CC'], ['D'], ['EEE', 'EEEE', 'EE', 'E']]
Assign each item a "positional value". Items in one category should be uniformly spaced, but with some randomness. To achieve this, do the following operations on each category having
nitems:- Initialize the positional value vector
vof lengthnwith the valuesv[k] = k/nfor0 <= k < n(i.e. 0-indexed), so that the items have default spacing of1/n. - Generate an initial random offset
iowithin the range of0 <= io <= 1/n, and add it to everyv[k]. Generate
nindividual random offsetso[k]within the range of-1/10n <= o[k] <= 1/10n, and applyv[k] += o[k]for eachk. So the positional value ofk-th item (0-indexed) within ann-item category will bev[k] = k/n + io + o[k].- The random offsets
ioando[k]should ideally be picked from a uniform random variable, but can be approximated by picking from a discrete distribution with at least 5 distinct equally-spaced outcomes, including both lower and upper bounds. (e.g. you can choose to randomly pickiofrom[0, 1/4n, 2/4n, 3/4n, 1/n].) - Don't do extra processing even if
v[k] < 0orv[k] > 1.
- The random offsets
- Initialize the positional value vector
[['AAA' -> 0.1, 'A' -> 0.41, 'AA' -> 0.79],
['B' -> 0.2],
['C' -> 0.49, 'CC' -> 1.01],
['D' -> 0.03],
['EEE' -> 0.12, 'EEEE' -> 0.37, 'EE' -> 0.6, 'E' -> 0.88]]
- Sort all items by the positional values.
['D', 'AAA', 'EEE', 'B', 'EEEE', 'A', 'C', 'EE', 'AA', 'E', 'CC']
The shuffled result roughly looks like this (from the article):
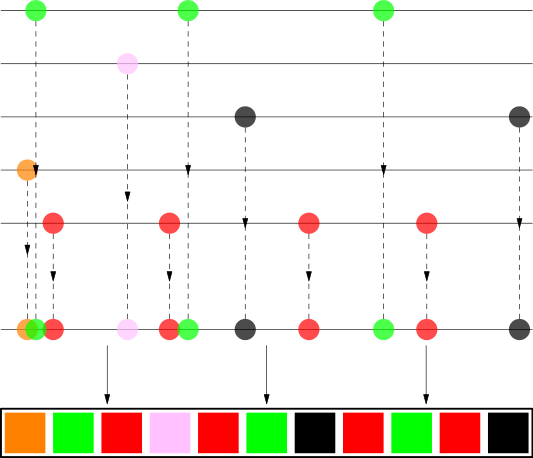
Here is Python-like pseudocode of the above algorithm:
x = nested array of items
uniform(a,b) = uniformly generate a random value between a and b
items = []
v = []
for i in range(len(x)): # for each category
shuffle(x[i]) # shuffle items within category in place
items += x[i]
n = len(x[i]) # size of the current category
io = uniform(0, 1/n) # initial offset
o = [uniform(-0.1/n, 0.1/n) for k in range(n)] # individual offsets
v += [k/n + io + o[k] for k in range(n)] # resulting positional values
sort items by v
print items
Input and output
The input is a list of groups of items (i.e. a nested list) as shown in the example above. An item is a string made of only uppercase letters (or only lowercase if you want). You can assume that all items are distinct, within and across categories.
The output is a shuffled list including all items in the input, which is produced by the algorithm described above.
The randomness requirements are covered in the algorithm description.
Scoring and winning criterion
Standard code-golf rules apply. Shortest code in bytes wins.

Bubbler
Posted 2020-01-16T23:52:10.757
Reputation: 16 616









"You may use any shuffle algorithm that can produce every possible permutation with nonzero probability." - does this make the assumption that you have a true randomness source? Because it's important to note that the number of possible permutations is limited by the period of the random number generator in use. – Beefster – 2020-01-17T23:13:32.057
That minimum bound of 5 was so convenient for my answer - it lets me generate a random number from
0to4, halve it, decrement it, and divide by 10, to give me a random number from-0.1to0.1. Thanks! – Neil – 2020-01-18T01:10:27.543@Beefster I'm aware of it, so it's OK to assume the underlying source of randomness for your language is perfect (i.e. true random). – Bubbler – 2020-01-18T08:18:33.583
May we assume no duplicates in the groups? – Jitse – 2020-01-20T13:16:58.627
@Jitse
You can assume that all items are distinct, so yes. – Bubbler – 2020-01-20T22:49:40.220