Alright. I spent around 30 minutes on this answer (current record). It's really optimal answer. Albeit not so fast and not so memory-exhausting (only ~512 megabytes), it's still a Malbolge answer so please keep that noted.
The program is packed using 7zip and PPMd compression algorithm. You can download it here.
Interpreter that works the best with the program.
#include <malloc.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
const char* translation = "5z]&gqtyfr$(we4{WP)H-Zn,[%\\3dL+Q;>U!pJS72Fh"
"OA1CB6v^=I_0/8|jsb9m<.TVac`uY*MK'X~xDl}REokN:#?G\"i@";
typedef struct Word {
unsigned int area;
unsigned int high;
unsigned int low;
} Word;
void word2string(Word w, char* s, int min_length) {
if (!s) return;
if (min_length < 1) min_length = 1;
if (min_length > 20) min_length = 20;
s[0] = (w.area%3) + '0';
s[1] = 't';
char tmp[20];
int i;
for (i=0;i<10;i++) {
tmp[19-i] = (w.low % 3) + '0';
w.low /= 3;
}
for (i=0;i<10;i++) {
tmp[9-i] = (w.high % 3) + '0';
w.high /= 3;
}
i = 0;
while (tmp[i] == s[0] && i < 20 - min_length) i++;
int j = 2;
while (i < 20) {
s[j] = tmp[i];
i++;
j++;
}
s[j] = 0;
}
unsigned int crazy_low(unsigned int a, unsigned int d){
unsigned int crz[] = {1,0,0,1,0,2,2,2,1};
int position = 0;
unsigned int output = 0;
while (position < 10){
unsigned int i = a%3;
unsigned int j = d%3;
unsigned int out = crz[i+3*j];
unsigned int multiple = 1;
int k;
for (k=0;k<position;k++)
multiple *= 3;
output += multiple*out;
a /= 3;
d /= 3;
position++;
}
return output;
}
Word zero() {
Word result = {0, 0, 0};
return result;
}
Word increment(Word d) {
d.low++;
if (d.low >= 59049) {
d.low = 0;
d.high++;
if (d.high >= 59049) {
fprintf(stderr,"error: overflow\n");
exit(1);
}
}
return d;
}
Word decrement(Word d) {
if (d.low == 0) {
d.low = 59048;
d.high--;
}else{
d.low--;
}
return d;
}
Word crazy(Word a, Word d){
Word output;
unsigned int crz[] = {1,0,0,1,0,2,2,2,1};
output.area = crz[a.area+3*d.area];
output.high = crazy_low(a.high, d.high);
output.low = crazy_low(a.low, d.low);
return output;
}
Word rotate_r(Word d){
unsigned int carry_h = d.high%3;
unsigned int carry_l = d.low%3;
d.high = 19683 * carry_l + d.high / 3;
d.low = 19683 * carry_h + d.low / 3;
return d;
}
// last_initialized: if set, use to fill newly generated memory with preinitial values...
Word* ptr_to(Word** mem[], Word d, unsigned int last_initialized) {
if ((mem[d.area])[d.high]) {
return &(((mem[d.area])[d.high])[d.low]);
}
(mem[d.area])[d.high] = (Word*)malloc(59049 * sizeof(Word));
if (!(mem[d.area])[d.high]) {
fprintf(stderr,"error: out of memory.\n");
exit(1);
}
if (last_initialized) {
Word repitition[6];
repitition[(last_initialized-1) % 6] =
((mem[0])[(last_initialized-1) / 59049])
[(last_initialized-1) % 59049];
repitition[(last_initialized) % 6] =
((mem[0])[last_initialized / 59049])
[last_initialized % 59049];
unsigned int i;
for (i=0;i<6;i++) {
repitition[(last_initialized+1+i) % 6] =
crazy(repitition[(last_initialized+i) % 6],
repitition[(last_initialized-1+i) % 6]);
}
unsigned int offset = (59049*d.high) % 6;
i = 0;
while (1){
((mem[d.area])[d.high])[i] = repitition[(i+offset)%6];
if (i == 59048) {
break;
}
i++;
}
}
return &(((mem[d.area])[d.high])[d.low]);
}
unsigned int get_instruction(Word** mem[], Word c,
unsigned int last_initialized,
int ignore_invalid) {
Word* instr = ptr_to(mem, c, last_initialized);
unsigned int instruction = instr->low;
instruction = (instruction+c.low + 59049 * c.high
+ (c.area==1?52:(c.area==2?10:0)))%94;
return instruction;
}
int main(int argc, char* argv[]) {
Word** memory[3];
int i,j;
for (i=0; i<3; i++) {
memory[i] = (Word**)malloc(59049 * sizeof(Word*));
if (!memory) {
fprintf(stderr,"not enough memory.\n");
return 1;
}
for (j=0; j<59049; j++) {
(memory[i])[j] = 0;
}
}
Word a, c, d;
unsigned int result;
FILE* file;
if (argc < 2) {
// read program code from STDIN
file = stdin;
}else{
file = fopen(argv[1],"rb");
}
if (file == NULL) {
fprintf(stderr, "File not found: %s\n",argv[1]);
return 1;
}
a = zero();
c = zero();
d = zero();
result = 0;
while (!feof(file)){
unsigned int instr;
Word* cell = ptr_to(memory, d, 0);
(*cell) = zero();
result = fread(&cell->low,1,1,file);
if (result > 1)
return 1;
if (result == 0 || cell->low == 0x1a || cell->low == 0x04)
break;
instr = (cell->low + d.low + 59049*d.high)%94;
if (cell->low == ' ' || cell->low == '\t' || cell->low == '\r'
|| cell->low == '\n');
else if (cell->low >= 33 && cell->low < 127 &&
(instr == 4 || instr == 5 || instr == 23 || instr == 39
|| instr == 40 || instr == 62 || instr == 68
|| instr == 81)) {
d = increment(d);
}
}
if (file != stdin) {
fclose(file);
}
unsigned int last_initialized = 0;
while (1){
*ptr_to(memory, d, 0) = crazy(*ptr_to(memory, decrement(d), 0),
*ptr_to(memory, decrement(decrement(d)), 0));
last_initialized = d.low + 59049*d.high;
if (d.low == 59048) {
break;
}
d = increment(d);
}
d = zero();
unsigned int step = 0;
while (1) {
unsigned int instruction = get_instruction(memory, c,
last_initialized, 0);
step++;
switch (instruction){
case 4:
c = *ptr_to(memory,d,last_initialized);
break;
case 5:
if (!a.area) {
printf("%c",(char)(a.low + 59049*a.high));
}else if (a.area == 2 && a.low == 59047
&& a.high == 59048) {
printf("\n");
}
break;
case 23:
a = zero();
a.low = getchar();
if (a.low == EOF) {
a.low = 59048;
a.high = 59048;
a.area = 2;
}else if (a.low == '\n'){
a.low = 59047;
a.high = 59048;
a.area = 2;
}
break;
case 39:
a = (*ptr_to(memory,d,last_initialized)
= rotate_r(*ptr_to(memory,d,last_initialized)));
break;
case 40:
d = *ptr_to(memory,d,last_initialized);
break;
case 62:
a = (*ptr_to(memory,d,last_initialized)
= crazy(a, *ptr_to(memory,d,last_initialized)));
break;
case 81:
return 0;
case 68:
default:
break;
}
Word* mem_c = ptr_to(memory, c, last_initialized);
mem_c->low = translation[mem_c->low - 33];
c = increment(c);
d = increment(d);
}
return 0;
}
It works!
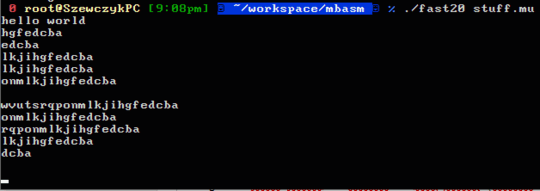




















































2May we output a list of strings instead of a single string with linefeeds? – Arnauld – 2019-11-21T13:10:17.680
@Arnauld Fine with me – AJFaraday – 2019-11-21T13:10:31.270
@Shaggy That's correct, from 'the task':
The input string may only contain the lower-case letters a-z and the space character.We can assume this, so there's no need for input validation. – AJFaraday – 2019-11-21T13:28:34.570Can we have spaces between the letters in the output eg
d c b a? – Jonah – 2019-11-21T19:58:39.69312I don't think a single answer uses recursion – Jo King – 2019-11-22T01:39:25.987
3“Human readable” prohibits most of the languages popular here! – WGroleau – 2019-11-22T02:50:10.790
@Jonah that’s fine. – AJFaraday – 2019-11-22T06:44:51.023
@WGroleau if I’m unable to parse the result, how should I know if it’s a valid answer? – AJFaraday – 2019-11-22T06:45:52.470
1
I was expecting a challenge where you had to write point-free code.
– user2357112 supports Monica – 2019-11-22T08:05:26.957If it passes all your test cases, then either it meets the requirements or your test cases are incorrect. Don’t get me wrong—after nearly forty years in software engineering, the last thing I’d do would be to encourage unreadable code. I just stop in here occasionally to see what the most extreme examples look like. – WGroleau – 2019-11-22T08:57:25.650
2@WGroleau Ah, I think I've spotted what's gone wrong here. I didn't require that the code should be human-readable, only the result. – AJFaraday – 2019-11-22T09:13:31.683
@user2357112supportsMonica Nope, just me being frustrated at the time. – AJFaraday – 2019-11-22T10:26:38.077
3Recursion is never necessary. At the very worst, you can just use stack data structure to have your own "recursion" in a flat loop, ending when the stack is empty. – Tomáš Zato - Reinstate Monica – 2019-11-22T11:41:50.117
May we have a leading newline character, before printing each line of text? – dingledooper – 2019-11-23T20:38:01.347