Java + Tesseract, 53 bytes
Since I don't have Mathematica, I decided to bend the rules a bit and use Tesseract to do the OCR. I wrote a program that renders "2014" into an image, using various fonts, sizes and styles, and finds the smallest image that gets recognized as "2014". Results depend on the available fonts.
Here is the winner on my computer - 53 bytes, using the "URW Gothic L" font: 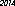
Code:
import java.awt.Color;
import java.awt.Font;
import java.awt.FontMetrics;
import java.awt.Graphics2D;
import java.awt.GraphicsEnvironment;
import java.awt.image.BufferedImage;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import javax.imageio.ImageIO;
public class Ocr {
public static boolean blankLine(final BufferedImage img, final int x1, final int y1, final int x2, final int y2) {
final int d = x2 - x1 + y2 - y1 + 1;
final int dx = (x2 - x1 + 1) / d;
final int dy = (y2 - y1 + 1) / d;
for (int i = 0, x = x1, y = y1; i < d; ++i, x += dx, y += dy) {
if (img.getRGB(x, y) != -1) {
return false;
}
}
return true;
}
public static BufferedImage trim(final BufferedImage img) {
int x1 = 0;
int y1 = 0;
int x2 = img.getWidth() - 1;
int y2 = img.getHeight() - 1;
while (x1 < x2 && blankLine(img, x1, y1, x1, y2)) x1++;
while (x1 < x2 && blankLine(img, x2, y1, x2, y2)) x2--;
while (y1 < y2 && blankLine(img, x1, y1, x2, y1)) y1++;
while (y1 < y2 && blankLine(img, x1, y2, x2, y2)) y2--;
return img.getSubimage(x1, y1, x2 - x1 + 1, y2 - y1 + 1);
}
public static int render(final Font font, final int w, final String name) throws IOException {
BufferedImage img = new BufferedImage(w, w, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = img.createGraphics();
float size = font.getSize2D();
Font f = font;
while (true) {
final FontMetrics fm = g.getFontMetrics(f);
if (fm.stringWidth("2014") <= w) {
break;
}
size -= 0.5f;
f = f.deriveFont(size);
}
g = img.createGraphics();
g.setFont(f);
g.fillRect(0, 0, w, w);
g.setColor(Color.BLACK);
g.drawString("2014", 0, w - 1);
g.dispose();
img = trim(img);
final File file = new File(name);
ImageIO.write(img, "gif", file);
return (int) file.length();
}
public static boolean ocr() throws Exception {
Runtime.getRuntime().exec("/usr/bin/tesseract 2014.gif out -psm 8").waitFor();
String t = "";
final BufferedReader br = new BufferedReader(new FileReader("out.txt"));
while (true) {
final String s = br.readLine();
if (s == null) break;
t += s;
}
br.close();
return t.trim().equals("2014");
}
public static void main(final String... args) throws Exception {
int min = 10000;
for (String s : GraphicsEnvironment.getLocalGraphicsEnvironment().getAvailableFontFamilyNames()) {
for (int t = 0; t < 4; ++t) {
final Font font = new Font(s, t, 50);
for (int w = 10; w < 25; ++w) {
final int size = render(font, w, "2014.gif");
if (size < min && ocr()) {
render(font, w, "2014win.gif");
min = size;
System.out.println(s + ", " + size);
}
}
}
}
}
}
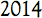 to 2014. I'd like to take this challenge in a different direction. Using built-in OCR from the language/standard library of your choice, design the smallest image (in bytes) which is parsed into the ASCII string "2014".
to 2014. I'd like to take this challenge in a different direction. Using built-in OCR from the language/standard library of your choice, design the smallest image (in bytes) which is parsed into the ASCII string "2014".
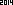
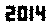


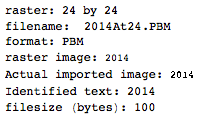

 . This is not optimized in any way; it's just Geneva in a small font size; other fonts and smaller sizes may be possible. Straight TextRecognize[] would fail, but TextRecognize[ImageResize[]]] has no problem
. This is not optimized in any way; it's just Geneva in a small font size; other fonts and smaller sizes may be possible. Straight TextRecognize[] would fail, but TextRecognize[ImageResize[]]] has no problem 

9How many languages or standard libraries have built-in OCR? Or do you intend "standard library" here to mean "any library which hasn't been created specifically for this challenge"? – Peter Taylor – 2014-01-05T08:25:30.420
3Does any development platform other than Mathematica have OCR built in? – Michael Stern – 2014-01-05T15:44:55.747
You should standardize, say something like "use http://www.free-ocr.com/" or some other easily accessible ocr.
– Justin – 2014-01-05T16:10:21.327