Part 4: QFTASM and Cogol
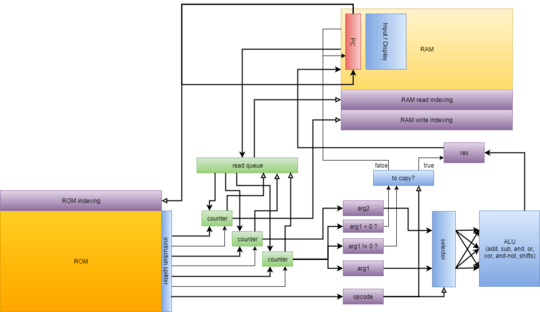
Architecture Overview
In short, our computer has a 16-bit asynchronous RISC Harvard architecture. When building a processor by hand, a RISC (reduced instruction set computer) architecture is practically a requirement. In our case, this means that the number of opcodes is small and, much more importantly, that all instructions are processed in a very similar manner.
For reference, the Wireworld computer used a transport-triggered architecture, in which the only instruction was MOV and computations were performed by writing/reading special registers. Although this paradigm leads to a very easy-to-implement architecture, the result is also borderline unusable: all arithmetic/logic/conditional operations require three instructions. It was clear to us that we wanted to create a much less esoteric architecture.
In order to keep our processor simple while increasing usability, we made several important design decisions:
- No registers. Every address in RAM is treated equally and can be used as any argument for any operation. In a sense, this means all of RAM could be treated like registers. This means that there are no special load/store instructions.
- In a similar vein, memory-mapping. Everything that could be written to or read from shares a unified addressing scheme. This means that the program counter (PC) is address 0, and the only difference between regular instructions and control-flow instructions is that control-flow instructions use address 0.
- Data is serial in transmission, parallel in storage. Due to the "electron"-based nature of our computer, addition and subtraction are significantly easier to implement when the data is transmitted in serial little-endian (least-significant bit first) form. Furthermore, serial data removes the need for cumbersome data buses, which are both really wide and cumbersome to time properly (in order for the data to stay together, all "lanes" of the bus must experience the same travel delay).
- Harvard architecture, meaning a division between program memory (ROM) and data memory (RAM). Although this does reduce the flexibility of the processor, this helps with size optimization: the length of the program is much larger than the amount of RAM we'll need, so we can split the program off into ROM and then focus on compressing the ROM, which is much easier when it is read-only.
- 16-bit data width. This is the smallest power of two that is wider than a standard Tetris board (10 blocks). This gives us a data range of -32768 to +32767 and a maximum program length of 65536 instructions. (2^8=256 instructions is enough for most simple things we might want a toy processor to do, but not Tetris.)
- Asynchronous design. Rather than having a central clock (or, equivalently, several clocks) dictating the timing of the computer, all data is accompanied by a "clock signal" which travels in parallel with the data as it flows around the computer. Certain paths may be shorter than others, and while this would pose difficulties for a centrally-clocked design, an asynchronous design can easily deal with variable-time operations.
- All instructions are of equal size. We felt that an architecture in which each instruction has 1 opcode with 3 operands (value value destination) was the most flexible option. This encompasses binary data operations as well as conditional moves.
- Simple addressing mode system. Having a variety of addressing modes is very useful for supporting things such as arrays or recursion. We managed to implement several important addressing modes with a relatively simple system.
An illustration of our architecture is contained in the overview post.
Functionality and ALU Operations
From here, it was a matter of determining what functionality our processor should have. Special attention was paid to the ease of implementation as well as the versatility of each command.
Conditional Moves
Conditional moves are very important and serve as both small-scale and large-scale control flow. "Small-scale" refers to its ability to control the execution of a particular data move, while "large-scale" refers to its use as a conditional jump operation to transfer control flow to any arbitrary piece of code. There are no dedicated jump operations because, due to memory mapping, a conditional move can both copy data to regular RAM and copy a destination address to the PC. We also chose to forgo both unconditional moves and unconditional jumps for a similar reason: both can be implemented as a conditional move with a condition that's hardcoded to TRUE.
We chose to have two different types of conditional moves: "move if not zero" (MNZ) and "move if less than zero" (MLZ). Functionally, MNZ amounts to checking whether any bit in the data is a 1, while MLZ amounts to checking if the sign bit is 1. They are useful for equalities and comparisons, respectively. The reason we chose these two over others such as "move if zero" (MEZ) or "move if greater than zero" (MGZ) was that MEZ would require creating a TRUE signal from an empty signal, while MGZ is a more complex check, requiring the the sign bit be 0 while at least one other bit be 1.
Arithmetic
The next-most important instructions, in terms of guiding the processor design, are the basic arithmetic operations. As I mentioned earlier, we are using little-endian serial data, with the choice of endianness determined by the ease of addition/subtraction operations. By having the least-significant bit arrive first, the arithmetic units can easily keep track of the carry bit.
We chose to use 2's complement representation for negative numbers, since this makes addition and subtraction more consistent. It's worth noting that the Wireworld computer used 1's complement.
Addition and subtraction are the extent of our computer's native arithmetic support (besides bit shifts which are discussed later). Other operations, like multiplication, are far too complex to be handled by our architecture, and must be implemented in software.
Bitwise Operations
Our processor has AND, OR, and XOR instructions which do what you would expect. Rather than have a NOT instruction, we chose to have an "and-not" (ANT) instruction. The difficulty with the NOT instruction is again that it must create signal from a lack of signal, which is difficult with a cellular automata. The ANT instruction returns 1 only if the first argument bit is 1 and the second argument bit is 0. Thus, NOT x is equivalent to ANT -1 x (as well as XOR -1 x). Furthermore, ANT is versatile and has its main advantage in masking: in the case of the Tetris program we use it to erase tetrominoes.
Bit Shifting
The bit-shifting operations are the most complex operations handled by the ALU. They take two data inputs: a value to shift and an amount to shift it by. Despite their complexity (due to the variable amount of shifting), these operations are crucial for many important tasks, including the many "graphical" operations involved in Tetris. Bit shifts would also serve as the foundation for efficient multiplication/division algorithms.
Our processor has three bit shift operations, "shift left" (SL), "shift right logical" (SRL), and "shift right arithmetic" (SRA). The first two bit shifts (SL and SRL) fill in the new bits with all zeros (meaning that a negative number shifted right will no longer be negative). If the second argument of the shift is outside the range of 0 to 15, the result is all zeros, as you might expect. For the last bit shift, SRA, the bit shift preserves the sign of the input, and therefore acts as a true division by two.
Instruction Pipelining
Now's the time to talk about some of the gritty details of the architecture. Each CPU cycle consists of the following five steps:
1. Fetch the current instruction from ROM
The current value of the PC is used to fetch the corresponding instruction from ROM. Each instruction has one opcode and three operands. Each operand consists of one data word and one addressing mode. These parts are split from each other as they are read from the ROM.
The opcode is 4 bits to support 16 unique opcodes, of which 11 are assigned:
0000 MNZ Move if Not Zero
0001 MLZ Move if Less than Zero
0010 ADD ADDition
0011 SUB SUBtraction
0100 AND bitwise AND
0101 OR bitwise OR
0110 XOR bitwise eXclusive OR
0111 ANT bitwise And-NoT
1000 SL Shift Left
1001 SRL Shift Right Logical
1010 SRA Shift Right Arithmetic
1011 unassigned
1100 unassigned
1101 unassigned
1110 unassigned
1111 unassigned
2. Write the result (if necessary) of the previous instruction to RAM
Depending on the condition of the previous instruction (such as the value of the first argument for a conditional move), a write is performed. The address of the write is determined by the third operand of the previous instruction.
It is important to note that writing occurs after instruction fetching. This leads to the creation of a branch delay slot in which the instruction immediately after a branch instruction (any operation which writes to the PC) is executed in lieu of the first instruction at the branch target.
In certain instances (like unconditional jumps), the branch delay slot can be optimized away. In other cases it cannot, and the instruction after a branch must be left empty. Furthermore, this type of delay slot means that branches must use a branch target that is 1 address less than the actual target instruction, to account for the PC increment that occurs.
In short, because the previous instruction's output is written to RAM after the next instruction is fetched, conditional jumps need to have a blank instruction after them, or else the PC won't be updated properly for the jump.
3. Read the data for the current instruction's arguments from RAM
As mentioned earlier, each of the three operands consists of both a data word and an addressing mode. The data word is 16 bits, the same width as RAM. The addressing mode is 2 bits.
Addressing modes can be a source of significant complexity for a processor like this, as many real-world addressing modes involve multi-step computations (like adding offsets). At the same time, versatile addressing modes play an important role in the usability of the processor.
We sought to unify the concepts of using hard-coded numbers as operands and using data addresses as operands. This led to the creation of counter-based addressing modes: the addressing mode of an operand is simply a number representing how many times the data should be sent around a RAM read loop. This encompasses immediate, direct, indirect, and double-indirect addressing.
00 Immediate: A hard-coded value. (no RAM reads)
01 Direct: Read data from this RAM address. (one RAM read)
10 Indirect: Read data from the address given at this address. (two RAM reads)
11 Double-indirect: Read data from the address given at the address given by this address. (three RAM reads)
After this dereferencing is performed, the three operands of the instruction have different roles. The first operand is usually the first argument for a binary operator, but also serves as the condition when the current instruction is a conditional move. The second operand serves as the second argument for a binary operator. The third operand serves as the destination address for the result of the instruction.
Since the first two instructions serve as data while the third serves as an address, the addressing modes have slightly different interpretations depending on which position they are used in. For example, the direct mode is used to read data from a fixed RAM address (since one RAM read is needed), but the immediate mode is used to write data to a fixed RAM address (since no RAM reads are necessary).
4. Compute the result
The opcode and the first two operands are sent to the ALU to perform a binary operation. For the arithmetic, bitwise, and shift operations, this means performing the relevant operation. For the conditional moves, this means simply returning the second operand.
The opcode and first operand are used to compute the condition, which determines whether or not to write the result to memory. In the case of conditional moves, this means either determining whether any bit in the operand is 1 (for MNZ), or determining whether the sign bit is 1 (for MLZ). If the opcode isn't a conditional move, then write is always performed (the condition is always true).
5. Increment the program counter
Finally, the program counter is read, incremented, and written.
Due to the position of the PC increment between the instruction read and the instruction write, this means that an instruction which increments the PC by 1 is a no-op. An instruction that copies the PC to itself causes the next instruction to be executed twice in a row. But, be warned, multiple PC instructions in a row can cause complex effects, including infinite looping, if you don't pay attention to the instruction pipeline.
Quest for Tetris Assembly
We created a new assembly language named QFTASM for our processor. This assembly language corresponds 1-to-1 with the machine code in the computer's ROM.
Any QFTASM program is written as a series of instructions, one per line. Each line is formatted like this:
[line numbering] [opcode] [arg1] [arg2] [arg3]; [optional comment]
Opcode List
As discussed earlier, there are eleven opcodes supported by the computer, each of which have three operands:
MNZ [test] [value] [dest] – Move if Not Zero; sets [dest] to [value] if [test] is not zero.
MLZ [test] [value] [dest] – Move if Less than Zero; sets [dest] to [value] if [test] is less than zero.
ADD [val1] [val2] [dest] – ADDition; store [val1] + [val2] in [dest].
SUB [val1] [val2] [dest] – SUBtraction; store [val1] - [val2] in [dest].
AND [val1] [val2] [dest] – bitwise AND; store [val1] & [val2] in [dest].
OR [val1] [val2] [dest] – bitwise OR; store [val1] | [val2] in [dest].
XOR [val1] [val2] [dest] – bitwise XOR; store [val1] ^ [val2] in [dest].
ANT [val1] [val2] [dest] – bitwise And-NoT; store [val1] & (![val2]) in [dest].
SL [val1] [val2] [dest] – Shift Left; store [val1] << [val2] in [dest].
SRL [val1] [val2] [dest] – Shift Right Logical; store [val1] >>> [val2] in [dest]. Doesn't preserve sign.
SRA [val1] [val2] [dest] – Shift Right Arithmetic; store [val1] >> [val2] in [dest], while preserving sign.
Addressing Modes
Each of the operands contains both a data value and an addressing move. The data value is described by a decimal number in the range -32768 to 32767. The addressing mode is described by a one-letter prefix to the data value.
mode name prefix
0 immediate (none)
1 direct A
2 indirect B
3 double-indirect C
Example Code
Fibonacci sequence in five lines:
0. MLZ -1 1 1; initial value
1. MLZ -1 A2 3; start loop, shift data
2. MLZ -1 A1 2; shift data
3. MLZ -1 0 0; end loop
4. ADD A2 A3 1; branch delay slot, compute next term
This code computes the Fibonacci sequence, with RAM address 1 containing the current term. It quickly overflows after 28657.
Gray code:
0. MLZ -1 5 1; initial value for RAM address to write to
1. SUB A1 5 2; start loop, determine what binary number to covert to Gray code
2. SRL A2 1 3; shift right by 1
3. XOR A2 A3 A1; XOR and store Gray code in destination address
4. SUB B1 42 4; take the Gray code and subtract 42 (101010)
5. MNZ A4 0 0; if the result is not zero (Gray code != 101010) repeat loop
6. ADD A1 1 1; branch delay slot, increment destination address
This program computes Gray code and stores the code in succesive addresses starting at address 5. This program utilizes several important features such as indirect addressing and a conditional jump. It halts once the resultant Gray code is 101010, which happens for input 51 at address 56.
Online Interpreter
El'endia Starman has created a very useful online interpreter here. You are able to step through the code, set breakpoints, perform manual writes to RAM, and visualize the RAM as a display.
Cogol
Once the architecture and assembly language were defined, the next step on the "software" side of the project was the creation of a higher-level language, something suitable for Tetris. Thus I created Cogol. The name is both a pun on "COBOL" and an acronym for "C of Game of Life", although it is worth noting that Cogol is to C what our computer is to an actual computer.
Cogol exists at a level just above assembly language. Generally, most lines in a Cogol program each correspond to a single line of assembly, but there are some important features of the language:
- Basic features include named variables with assignments and operators that have more readable syntax. For example,
ADD A1 A2 3 becomes z = x + y;, with the compiler mapping variables onto addresses.
- Looping constructs such as
if(){}, while(){}, and do{}while(); so the compiler handles branching.
- One-dimensional arrays (with pointer arithmetic), which are used for the Tetris board.
- Subroutines and a call stack. These are useful for preventing duplication of large chunks of code, and for supporting recursion.
The compiler (which I wrote from scratch) is very basic/naive, but I've attempted to hand-optimize several of the language constructs to achieve a short compiled program length.
Here are some short overviews of how various language features work:
Tokenization
The source code is tokenized linearly (single-pass), using simple rules about which characters are allowed to be adjacent within a token. When a character is encountered that cannot be adjacent to the last character of the current token, the current token is deemed complete and the new character begins a new token. Some characters (such as { or ,) cannot be adjacent to any other characters and are therefore their own token. Others (like > or =) are only allowed to be adjacent to other characters within their class, and can thus form tokens like >>>, ==, or >=, but not like =2. Whitespace characters force a boundary between tokens but aren't themselves included in the result. The most difficult character to tokenize is - because it can both represent subtraction and unary negation, and thus requires some special-casing.
Parsing
Parsing is also done in a single-pass fashion. The compiler has methods for handling each of the different language constructs, and tokens are popped off of the global token list as they are consumed by the various compiler methods. If the compiler ever sees a token that it does not expect, it raises a syntax error.
Global Memory Allocation
The compiler assigns each global variable (word or array) its own designated RAM address(es). It is necessary to declare all variables using the keyword my so that the compiler knows to allocate space for it. Much cooler than named global variables is the scratch address memory management. Many instructions (notably conditionals and many array accesses) require temporary "scratch" addresses to store intermediate calculations. During the compilation process the compiler allocates and de-allocates scratch addresses as necessary. If the compiler needs more scratch addresses, it will dedicate more RAM as scratch addresses. I believe it's typical for a program to only require a few scratch addresses, although each scratch address will be used many times.
IF-ELSE Statements
The syntax for if-else statements is the standard C form:
other code
if (cond) {
first body
} else {
second body
}
other code
When converted to QFTASM, the code is arranged like this:
other code
condition test
conditional jump
first body
unconditional jump
second body (conditional jump target)
other code (unconditional jump target)
If the first body is executed, the second body is skipped over. If the first body is skipped over, the second body is executed.
In the assembly, a condition test is usually just a subtraction, and the sign of the result determines whether to make the jump or execute the body. An MLZ instruction is used to handle inequalities such as > or <=. An MNZ instruction is used to handle ==, since it jumps over the body when the difference is not zero (and therefore when the arguments are not equal). Multi-expression conditionals are not currently supported.
If the else statement is omitted, the unconditional jump is also omitted, and the QFTASM code looks like this:
other code
condition test
conditional jump
body
other code (conditional jump target)
WHILE Statements
The syntax for while statements is also the standard C form:
other code
while (cond) {
body
}
other code
When converted to QFTASM, the code is arranged like this:
other code
unconditional jump
body (conditional jump target)
condition test (unconditional jump target)
conditional jump
other code
The condition testing and conditional jump are at the end of the block, which means they are re-executed after each execution of the block. When the condition is returns false the body is not repeated and the loop ends. During the start of loop execution, control flow jumps over the loop body to the condition code, so the body is never executed if the condition is false the first time.
An MLZ instruction is used to handle inequalities such as > or <=. Unlike during if statements, an MNZ instruction is used to handle !=, since it jumps to the body when the difference is not zero (and therefore when the arguments are not equal).
DO-WHILE Statements
The only difference between while and do-while is that the a do-while loop body is not initially skipped over so it is always executed at least once. I generally use do-while statements to save a couple lines of assembly code when I know the loop will never need to be skipped entirely.
Arrays
One-dimensional arrays are implemented as contiguous blocks of memory. All arrays are fixed-length based on their declaration. Arrays are declared like so:
my alpha[3]; # empty array
my beta[11] = {3,2,7,8}; # first four elements are pre-loaded with those values
For the array, this is a possible RAM mapping, showing how addresses 15-18 are reserved for the array:
15: alpha
16: alpha[0]
17: alpha[1]
18: alpha[2]
The address labeled alpha is filled with a pointer to the location of alpha[0], so in thie case address 15 contains the value 16. The alpha variable can be used inside of the Cogol code, possibly as a stack pointer if you want to use this array as a stack.
Accessing the elements of an array is done with the standard array[index] notation. If the value of index is a constant, this reference is automatically filled in with the absolute address of that element. Otherwise it performs some pointer arithmetic (just addition) to find the desired absolute address. It is also possible to nest indexing, such as alpha[beta[1]].
Subroutines and Calling
Subroutines are blocks of code that can be called from multiple contexts, preventing duplication of code and allowing for the creation of recursive programs. Here is a program with a recursive subroutine to generate Fibonacci numbers (basically the slowest algorithm):
# recursively calculate the 10th Fibonacci number
call display = fib(10).sum;
sub fib(cur,sum) {
if (cur <= 2) {
sum = 1;
return;
}
cur--;
call sum = fib(cur).sum;
cur--;
call sum += fib(cur).sum;
}
A subroutine is declared with the keyword sub, and a subroutine can be placed anywhere inside the program. Each subroutine can have multiple local variables, which are declared as part of its list of arguments. These arguments can also be given default values.
In order to handle recursive calls, the local variables of a subroutine are stored on the stack. The last static variable in RAM is the call stack pointer, and all memory after that serves as the call stack. When a subroutine is called, it created a new frame on the call stack, which includes all local variables as well as the return (ROM) address. Each subroutine in the program is given a single static RAM address to serve as a pointer. This pointer gives the location of the "current" call of the subroutine in the call stack. Referencing a local variable is done using the value of this static pointer plus an offset to give the address of that particular local variable. Also contained in the call stack is the previous value of the static pointer. Here's the variables mapping of both the static RAM and the subroutine call frame for the above program:
RAM map:
0: pc
1: display
2: scratch0
3: fib
4: scratch1
5: scratch2
6: scratch3
7: call
fib map:
0: return
1: previous_call
2: cur
3: sum
One thing that is interesting about subroutines is that they do not return any particular value. Rather, all of the local variables of the subroutine can be read after the subroutine is performed, so a variety of data can be extracted from a subroutine call. This is accomplished by storing the pointer for that specific call of the subroutine, which can then be used to recover any of the local variables from within the (recently-deallocated) stack frame.
There are multiple ways to call a subroutine, all using the call keyword:
call fib(10); # subroutine is executed, no return vaue is stored
call pointer = fib(10); # execute subroutine and return a pointer
display = pointer.sum; # access a local variable and assign it to a global variable
call display = fib(10).sum; # immediately store a return value
call display += fib(10).sum; # other types of assignment operators can also be used with a return value
Any number of values can be given as arguments for a subroutine call. Any argument not provided will be filled in with its default value, if any. An argument that is not provided and has no default value is not cleared (to save instructions/time) so could potentially take on any value at the start of the subroutine.
Pointers are a way of accessing multiple local variables of subroutine, although it is important to note that the pointer is only temporary: the data the pointer points to will be destroyed when another subroutine call is made.
Debugging Labels
Any {...} code block in a Cogol program can be preceded by a multi-word descriptive label. This label is attached as a comment in the compiled assembly code, and can be very useful for debugging since it makes it easier to locate specific chunks of code.
Branch Delay Slot Optimization
In order to improve the speed of the compiled code, the Cogol compiler performs some really basic delay slot optimization as a final pass over the QFTASM code. For any unconditional jump with an empty branch delay slot, the delay slot can be filled by the first instruction at the jump destination, and the jump destination is incremented by one to point to the next instruction. This generally saves one cycle each time an unconditional jump is performed.
Writing the Tetris code in Cogol
The final Tetris program was written in Cogol, and the source code is available here. The compiled QFTASM code is available here. For convenience, a permalink is provided here: Tetris in QFTASM. Since the goal was to golf the assembly code (not the Cogol code), the resultant Cogol code is unwieldy. Many portions of the program would normally be located in subroutines, but those subroutines were actually short enough that duplicating the code saved instructions over the call statements. The final code only has one subroutine in addition to the main code. Additionally, many arrays were removed and replaced either with an equivalently-long list of individual variables, or by a lot of hard-coded numbers in the program. The final compiled QFTASM code is under 300 instructions, although it is only slightly longer than the Cogol source itself.























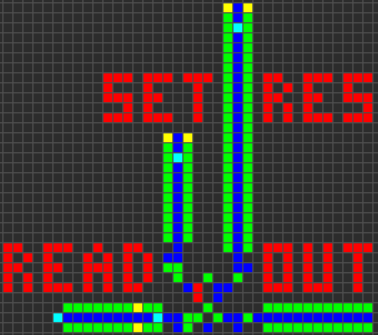





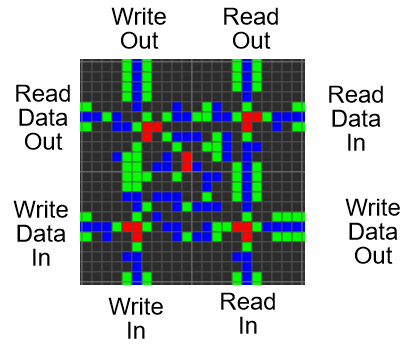

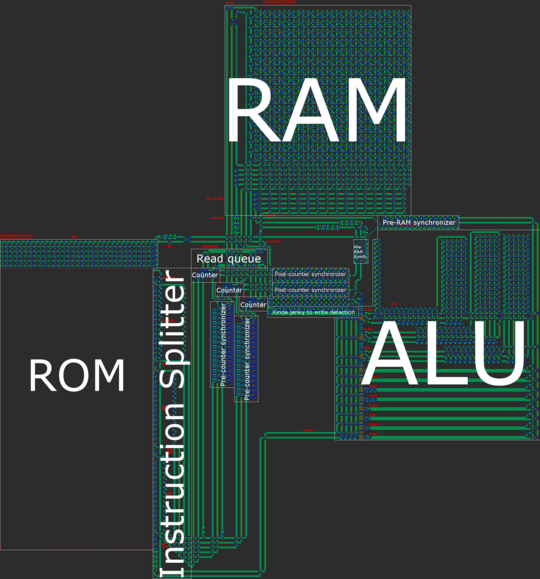





{kind=link}
{kind=link}
11@copy Oh my... I wish I could understand this. – mbomb007 – 2015-02-20T22:22:59.930
2@Nathaniel Preferably it would be a visible demonstration, since that's what the metapixels are for. – Joe Z. – 2015-02-21T00:03:08.757
6
@JanDvorak and PeterTaylor While it'll probably take a few thousand generations for the solution to complete a single iteration, it should be fairly easy to make it go by quickly. Golly and most other modern cellular automaton simulators have some form of speed control; in addition, since the solution will likely be repetitive, it'll cooperate nicely with Golly's Hashlife algorithm (ensuring that it'll run smoothly at any reasonably fast speed). Point being that we'll be able to see for ourselves that it works.
– M. I. Wright – 2015-07-14T22:50:44.7901Only a few thousand? Sounds more like it would take a few million. – Joe Z. – 2015-07-14T23:01:39.260
1The OTCA metapixel has a period of 35328; the tetris unit cell will be significantly less complicated than it (can't go into as much detail as I'd like to in 600 chars), so taking into consideration that Hashlife likes powers of two, I'd aim for around 2^14 gens. Also note that using a metapixel as opposed to a central processor of some sort will make features like rotation virtually impossible. [disclaimer: I may or may not be trying my hand at a solution] – M. I. Wright – 2015-07-19T01:23:03.013
1oh, but if the OTCA metapixel's p184 clock is used, it may be easier to keep the same timing. Not sure yet. – M. I. Wright – 2015-07-19T01:25:11.063
5@M.I.Wright If you do end up going all-in for a solution, good luck to you. We all want to see you succeed. – mbomb007 – 2015-07-28T20:26:36.023
1@M.I Wright: using a central processor is fine, but preferably the result would be visible on the screen. – Joe Z. – 2015-07-30T01:24:37.697
1
Of course! For a display I was thinking of giving data to this thing, which I think @copy posted up above if you want to see it in action... I've already started on a metapixel, though [is it fine if I submit two? :P]
– M. I. Wright – 2015-07-30T16:00:12.8203You can submit as many as you want; this question has gone unanswered for two years since I asked it. – Joe Z. – 2015-07-31T18:01:32.157
1@ghosts_in_the_code nope, just hit an unexpected roadblock; the metapixel was technically finished, but it didn't work at all since the whole idea of a metapixel is that it works independently. Tetris pieces, however, take up more than one pixel, so they need to be synchronized. I'm still working out the kinks in a new idea - I can actually post a diagram+some info on how it'd work if you're interested. – M. I. Wright – 2015-12-19T19:53:24.970
@M.I.Wright I'm not personally interested (neither am I capable) but I would recommend posting your progress anyway, because 1. People can help you find flaws in it. 2. Someone else may be able to solve it by building on your method. – ghosts_in_the_code – 2015-12-21T11:27:23.730
@M.I.Wright the OCTA metapixel's state change only depends on its eight neighbors. a tetris cell's state change depends on its whole row, among other things. even ignoring control input (assume we just need to simulate a step of a tetris field), the tetris metapixel is going to be much more complex than a game-of-life metapixel – Sparr – 2016-01-14T22:41:45.447
1@JoeZ. this challenge might be too hard. Perhaps consider reposting something much much simpler? A tic tac toe game in life might be plausible for multiple people here to accomplish in different ways. – Sparr – 2016-01-14T22:42:48.437
2I'll keep this one up, but I could definitely post a simpler one. – Joe Z. – 2016-01-14T23:00:24.580
@Sparr exactly! That's why I ditched the metapixel and am working on my new idea (which i'll get around to summarizing here sooner or later). I also kinda think that a tic tac toe game would be on about the same level of difficulty as this challenge. – M. I. Wright – 2016-01-16T04:56:02.643
@M.I.Wright tic tac toe should be roughly similar to the life metapixel. the result of a TTT game depends on just 9 cells. – Sparr – 2016-01-16T05:27:32.433
Just realised that this doesn't have a winning criterion other than "first to post". Once the first solution is posted, it may lower the barrier to entry and result in more solutions. Maybe it would be worth adding a winning criterion before the first solution comes in. Like starting position that fits in the smallest rectangular area, or fastest run speed in terms of arena ticks. That would allow for a basic first solution using existing components for pixels and logic gates, but still leave the competition open for more innovative customised solutions later. – trichoplax – 2016-05-27T00:42:44.690
@trichoplax Maybe something like "fewest initial cells filled in"? – Joe Z. – 2016-05-27T04:13:18.887
I wonder if this question can get to 100 upvotes without being answered. – Joe Z. – 2016-05-27T04:13:28.170
@JoeZ. that sounds good – trichoplax – 2016-05-27T17:45:48.653
If it affects your decision on whether to edit in a winning criterion, there's some discussion on meta about this specific challenge.
– trichoplax – 2016-05-30T22:15:09.86058This challenge is being worked on! Chat room | Progress | Blog – mbomb007 – 2016-06-13T19:16:16.673
Erm... How exactly does one provide input to said game? The standard Conway's Game Of Life provides no input other than the start state. – Pharap – 2016-07-21T02:36:48.333
3@Pharap As mentioned in the question statement, input is represented by manually changing the state of the automaton at a certain generation. – Joe Z. – 2016-07-25T04:39:04.660
49As of 5:10 this morning (9:10 UTC), this question is the first question in PPCG history to reach 100 votes without getting an answer! Well done everyone. – Joe Z. – 2016-09-14T12:45:19.070
@JoeZ. It probably won't reach 150 (un)fortunately! – wizzwizz4 – 2016-09-14T16:32:41.867
96Does "demonstrably working example" mean something that runs in a matter of hours, or something that can be proven correct even though it would take until the heat death of the universe to play? – Peter Taylor – 2013-06-18T09:36:58.620
1@PeterTaylor I'd say, given the solution would probably be slower than the decay of electrons, I'd say a mathematical-grade proof is required. – John Dvorak – 2013-06-18T11:02:59.367
3@PeterTaylor and JanDvorak Even a proof would be extremely complex. It is difficult to proove that any tetris program in any (much more suitable than GoL) high level programming language works as intended - even more if you have to construct something out of more elementary building blocks. – Howard – 2013-06-18T12:46:26.720
5I'd already be impressed if anyone can show me a single tetris block which rotates cw and ccw within a defined number of steps. (not the simple four tiles block ;-)) – Howard – 2013-06-18T12:48:27.743
3@Howard, I think a proof would have to be on the basis of "Here's a program you can examine; here's a compiler which I can prove correct". – Peter Taylor – 2013-06-18T12:56:04.627
10
A Bitmap Display has been created before. Anybody who gives this a attempt might want to use it.
– copy – 2013-06-18T14:16:32.7801@PeterTaylor: The latter would be fine. – Joe Z. – 2013-06-18T17:36:05.880
35I'm pretty sure something like this is possible and playable. It's just that very few people have the expertise to be able to program what is probably one of the more esoteric "assembly languages" in the world. – Justin L. – 2013-07-16T05:09:06.313
8@wizzwizz4 It probably will, actually. – ghosts_in_the_code – 2016-12-08T14:14:51.807
@SeeOneRhino Would the code written take any input? Otherwise it wouldn't really be a code challenge. – wizzwizz4 – 2016-12-08T20:33:31.640
@wizzwizz4 No, that was a joke. – NoOneIsHere – 2016-12-08T21:01:41.783
1Can you define "Tetris" a bit more? Otherwise I could submit one cell and win, because it is tetris, just too small to play. – NoOneIsHere – 2017-01-05T06:44:53.900
1@SeeOneRhino I'd assume "Tetris" to mean that you construct a metapixel-like thing that can be tiled to make as large of a board as necessary, but you'd need confirmation from OP. – HyperNeutrino – 2017-01-21T22:38:54.100
22Any valid answer to this will probably become the most upvoted answer on this site. – HyperNeutrino – 2017-01-21T22:39:24.653
77I am trying to solve this... Now, when I go to bed, I see gliders everywhere, colliding in a giant mess. My sleeps are full of nightmares where pulsating pentadecathlons block my way and Herschels are evolving to absorb me. Please, John Conway, pray for me... – dim lost faith in SE – 2017-03-07T19:50:35.213
2The question says "randomly" generate a piece. Where does one get a source of randomness in CGOL? There's no way to get the current generation or date/time as a seed for a PRNG or anything... – mbomb007 – 2017-04-05T21:30:16.413
2@mbomb007 - take the same approach as many older games do. You have a PRNG with a static seed, and user input is fed to it. This will have the downside that the first piece is always the same. Alternatively, have your user input setup also take a PRNG seed. – TLW – 2017-04-30T22:25:21.297
@TLW Taking the seed as input is probably the best way to ensure every game can be different. – mbomb007 – 2017-04-30T23:51:05.930
32Finally there's an answer, after four years. – Zacharý – 2017-09-14T15:36:19.453
1I'm surprised this hasn't made the HNQ (Hot Network Questions) list yet. – mbomb007 – 2017-09-15T15:31:42.013
3
Jeff Atwood recently retweeted a link to this question: https://twitter.com/balpha/status/908320205591511041
– Kevin Workman – 2017-09-15T21:06:40.2332@mbomb007 It's way too old for any amount of votes to get it onto the HNQ. – Martin Ender – 2017-09-18T09:44:34.370
4"Whats your favorite programing language?" "Conways game of life" – Vajura – 2018-01-30T08:10:08.617
exact definition of display? – l4m2 – 2018-04-03T12:16:53.683
has anyone seen my jaw? ... I dropped it somewhere on this page (near the very top!). This question and the answer is awe inspiring, and I'm glad it exists. Congrats to all involved – Olivier Dulac – 2019-07-22T16:44:06.217
9Do you actually have to be able to see the block rotating and falling etc., on the game of life grid, or is it enough just to have it logically represented somehow? If the latter then this task isn't impossibly hard - you can just take one of the existing Turing machine implementations, write a compiler for it (if that hasn't been done already), then code up Tetris in the language of your choice. But if the former then, well, I guess it's possible, but it would be a huge task for anyone to attempt. – Nathaniel – 2014-10-16T14:21:26.580