Mathematica
Decided to start again, now that I understand the rules of the game (I think).
A 10000 word dictionary of unique randomly composed "words" (lower case only) of length 3. In similar fashion other dictionaries were created consisting of strings of length 4, 5, 6, 7, and 8.
ClearAll[dictionary]
dictionary[chars_,nWords_]:=DeleteDuplicates[Table[FromCharacterCode@RandomInteger[{97,122},
chars],{nWords}]];
n=16000;
d3=Take[dictionary[3,n],10^4];
d4=Take[dictionary[4,n],10^4];
d5=Take[dictionary[5,n],10^4];
d6=Take[dictionary[6,n],10^4];
d7=Take[dictionary[7,n],10^4];
d8=Take[dictionary[8,n],10^4];
gtakes the current version of dictionary to check. The top word is joined with cyclic variants (if any exist). The word and its matches are appended to the output list, out, of processed words. The output words are removed from the dictionary.
g[{wds_,out_}] :=
If[wds=={},{wds,out},
Module[{s=wds[[1]],t,c},
t=Table[StringRotateLeft[s, k], {k, StringLength[s]}];
c=Intersection[wds,t];
{Complement[wds,t],Append[out,c]}]]
f runs through all words dictionary.
f[dict_]:=FixedPoint[g,{dict,{}}][[2]]
Example 1: actual words
r = f[{"teaks", "words", "spot", "pots", "sword", "steak", "hand"}]
Length[r]
{{"steak", "teaks"}, {"hand"}, {"pots", "spot"}, {"sword", "words"}}
4
Example 2: Artificial words. Dictionary of strings of length 3. First, timing. Then the number of cycle words.
f[d3]//AbsoluteTiming
Length[%[[2]]]
5402
Timings as a function of word length. 10000 words in each dictionary.
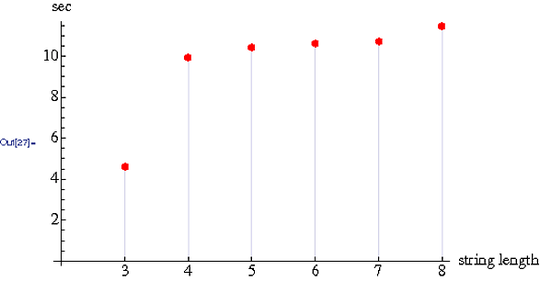
I don't particularly know how to interpret the findings in terms of O. In simple terms, the timing roughly doubles from the three character dictionary to the four character dictionary.
The timing increases almost negligibly from 4 through 8 characters.







3If you're looking for criticism of your code then the place to go is codereview.stackexchange.com . – Peter Taylor – 2013-01-17T08:21:05.460
Cool. I'll edit for emphasis on the challenge and move the criticism part to code review. Thanks Peter. – eggonlegs – 2013-01-17T08:31:23.887
1What's the winning criteria? Shortest code (Code Golf) or anything else? Are there any limitataions on the form of input and output? Do we need to write a function or a complete program? Does it have to be in Java? – ugoren – 2013-01-17T12:46:11.803
Well the ideal criteria I had in mind was big o time complexity, but we can do length if you like. Sorry, I am new to this. :/ – eggonlegs – 2013-01-17T13:42:21.103
@eggonlegs We are asking, not telling you about the criteria. It's just that this is a site where we pose and answer challanges, and we like them to have a metric that allows us to judge the "winner". Tags like code-golf, code-challenge, king-of-the-hill and details in the text are used to indicate the rules. [Code-challenge] is most general.
– dmckee --- ex-moderator kitten – 2013-01-17T14:00:11.803Understood. Okay, 'fastest-code' it is. :) – eggonlegs – 2013-01-17T14:05:33.213
1@eggonlegs You specified big-O - but with respect to which parameter? Number of strings in array? Is string comparison then O(1)? Or number of chars in string or total number of chars? Or anything else? – Howard – 2013-01-17T14:13:22.703
Sorry Howard, this was never really meant to be a code golf question, but I have updated it anyway. I want to take into account the speed of the comparison itself. – eggonlegs – 2013-01-17T14:41:29.950
@eggonlegs What is the count of the list {"teaks", "words", "spot", "pots", "sword", "steak", "hand"}? 3 or 6? – DavidC – 2013-01-17T20:52:30.477
1@dude, surely it's 4? – Peter Taylor – 2013-01-17T23:12:33.877
So. You group words together that are rotations of each other and then count the groups. Fair enough. – DavidC – 2013-01-17T23:50:13.240
@dude yes, it is 4 – eggonlegs – 2013-01-18T00:04:47.360
I'll try to do a better job posting a question next time ^_^ – eggonlegs – 2013-01-19T11:22:55.437