9
Given a series of numbers for events X and Y, calculate Pearson's correlation coefficient. The probability of each event is equal, so expected values can be calculated by simply summing each series and dividing by the number of trials.
Input
1 6.86
2 5.92
3 6.08
4 8.34
5 8.7
6 8.16
7 8.22
8 7.68
9 12.04
10 8.6
11 10.96
Output
0.769
Shortest code wins. Input can be by stdin or arg. Output will be by stdout.
Edit: Builtin functions should not be allowed (ie calculated expected value, variance, deviation, etc) to allow more diversity in solutions. However, feel free to demonstrate a language that is well suited for the task using builtins (for exhibition).
Based on David's idea for input for Mathematica (86 char using builtin mean)
m=Mean;x=d[[All,1]];y=d[[All,2]];(m@(x*y)-m@x*m@y)/Sqrt[(m@(x^2)-m@x^2)(m@(y^2)-m@y^2)]
m = Mean;
x = d[[All,1]];
y = d[[All,2]];
(m@(x*y) - m@x*m@y)/((m@(x^2) - m@x^2)(m@(y^2) - m@y^2))^.5
Skirting by using our own mean (101 char)
m=Total[#]/Length[#]&;x=d[[All,1]];y=d[[All,2]];(m@(x*y)-m@x*m@y)/((m@(x^2)-m@x^2)(m@(y^2)-m@y^2))^.5
m = Total[#]/Length[#]&;
x = d[[All,1]];
y = d[[All,2]];
(m@(x*y)-m@x*m@y)/((m@(x^2)-m@x^2)(m@(y^2)-m@y^2))^.5

miles
Posted 2012-11-28T22:32:28.043
Reputation: 15 654
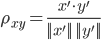
 are the input vectors
are the input vectors 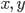 adjusted downwards by
adjusted downwards by 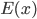 and
and 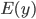 respectively.
respectively.







Very nice streamlining of the Mathematica code, using your own mean! – DavidC – 2012-11-29T14:18:13.863
The MMa code can be shortened. See my comment under David's answer. Also, in your code you may define
m=Total@#/Length@#&– Dr. belisarius – 2012-12-12T12:12:22.740