Also available at GitHub.
You need Dart 1.12 and Pub. Just run pub get to download the only
dependency, a parsing library.
Here's to hoping to this one lasts longer than 30 minutes! :O
The language
Zinc is oriented around redefining operators. You can redefine all the operators
in the language easily!
The structure of a typical Zinc program looks like:
let
<operator overrides>
in <expression>
There are only two data types: integers and sets. There is no such thing as a set
literal, and empty sets are disallowed.
Expressions
The following are valid expressions in Zinc:
Literals
Zinc supports all the normal integer literals, like 1 and -2.
Variables
Zinc has variables (like most languages). To reference them, just use the name.
Again like most languages!
However, there is a special variable called S that behaves kind of like Pyth's
Q. When you first use it, it will read in a line from standard input and
interpret it as a set of numbers. For instance, the input line 1234231 would
turn into the set {1, 2, 3, 4, 3, 2, 1}.
IMPORTANT NOTE!!! In some cases, a literal at the end of an operator override
is parsed incorrectly, so you have to surround it with parentheses.
Binary operations
The following binary operations are supported:
- Addition via
+: 1+1.
- Subtraction via
-: 1-1.
- Multiplication via
*: 2*2.
- Division via
/: 4/2.
- Equality with
=: 3=3.
Additionally, the following unary operation is also supported:
Precedence is always right-associative. You can use parentheses to override this.
Only equality and length work on sets. When you try to get the length of an
integer, you will get the number of digits in its string representation.
Set comprehensions
In order to manipulate sets, Zinc has set comprehensions. They look like this:
{<variable>:<set><clause>}
A clause is either a when clause or a sort clause.
A when clause looks like ^<expression>. The expression following the caret must
result in an integer. Using the when clause will take only the elements in the set
for which expression is non-zero. Within the expression, the variable _ will
be set to the current index in the set. It is roughly equivalent to this Python:
[<variable> for _, <variable> in enumerate(<set>) when <expression> != 0]
A sort clause, which looks like $<expression>, sorts the set descending by the
value of <expression>. It is equal to this Python:
sorted(<set>, key=lambda <variable>: <expression>)[::-1]
Here are some comprehension examples:
Overrides
Operator overrides allow you to redefine operators. They look like this:
<operator>=<operator>
or:
<variable><operator><variable>=<expression>
In the first case, you can define an operator to equal another operator. For
instance, I can define + to actually subtract via:
+=-
When you do this, you can redefine an operator to be a magic operator. There
are two magic operators:
join takes a set and an integer and joins the contents of the set. For
instance, joining {1, 2, 3} with 4 will result in the integer 14243.
cut also takes a set and an integer and will partition the set at every
occurence of the integer. Using cut on {1, 3, 9, 4, 3, 2} and 3 will
create {{1}, {9, 4}, {2}}...BUT any single-element sets are flattened, so the
result will actually be {1, {9, 4}, 2}.
Here's an example that redefines the + operator to mean join:
+=join
For the latter case, you can redefine an operator to the given expression. As an
example, this defines the plus operation to add the values and then add 1:
x+y=1+:x+:y
But what's +:? You can append the colon : to an operator to always use the
builtin version. This example uses the builtin + via +: to add the numbers
together, then it adds a 1 (remember, everything is right-associative).
Overriding the length operator looks kind of like:
#x=<expression>
Note that almost all the builtin operations (except equality) will use this
length operator to determine the length of the set. If you defined it to be:
#x=1
every part of Zinc that works on sets except = would only operate on the first
element of the set it was given.
Multiple overrides
You can override multiple operators by separating them with commas:
let
+=-,
*=/
in 1+2*3
Printing
You cannot directly print anything in Zinc. The result of the expression following in will be printed. The values of a set will be concatenated with to separator. For instance, take this:
let
...
in expr
If expr is the set {1, 3, {2, 4}}, 1324 will be printed to the screen once the program finishes.
Putting it all together
Here's a simple Zinc program that appears to add 2+2 but causes the result to be
5:
let
x+y=1+:x+:y
in 1+2
The interpreter
This goes in bin/zinc.dart:
import 'package:parsers/parsers.dart';
import 'dart:io';
// An error.
class Error implements Exception {
String cause;
Error(this.cause);
String toString() => 'error in Zinc script: $cause';
}
// AST.
class Node {
Obj interpret(ZincInterpreter interp) => null;
}
// Identifier.
class Id extends Node {
final String id;
Id(this.id);
String toString() => 'Id($id)';
Obj interpret(ZincInterpreter interp) => interp.getv(id);
}
// Integer literal.
class IntLiteral extends Node {
final int value;
IntLiteral(this.value);
String toString() => 'IntLiteral($value)';
Obj interpret(ZincInterpreter interp) => new IntObj(value);
}
// Any kind of operator.
class Anyop extends Node {
void set(ZincInterpreter interp, OpFuncType func) {}
}
// Operator.
class Op extends Anyop {
final String op;
final bool orig;
Op(this.op, [this.orig = false]);
String toString() => 'Op($op, $orig)';
OpFuncType get(ZincInterpreter interp) =>
this.orig ? interp.op0[op] : interp.op1[op];
void set(ZincInterpreter interp, OpFuncType func) { interp.op1[op] = func; }
}
// Unary operator (len).
class Lenop extends Anyop {
final bool orig;
Lenop([this.orig = false]);
String toString() => 'Lenop($orig)';
OpFuncType get(ZincInterpreter interp) =>
this.orig ? interp.op0['#'] : interp.op1['#'];
void set(ZincInterpreter interp, OpFuncType func) { interp.op1['#'] = func; }
}
// Magic operator.
class Magicop extends Anyop {
final String op;
Magicop(this.op);
String toString() => 'Magicop($op)';
Obj interpret_with(ZincInterpreter interp, Obj x, Obj y) {
if (op == 'cut') {
if (y is! IntObj) { throw new Error('cannot cut int with non-int'); }
if (x is IntObj) {
return new SetObj(x.value.toString().split(y.value.toString()).map(
int.parse));
} else {
assert(x is SetObj);
List<List<Obj>> res = [[]];
for (Obj obj in x.vals(interp)) {
if (obj == y) { res.add([]); }
else { res.last.add(obj); }
}
return new SetObj(new List.from(res.map((l) =>
l.length == 1 ? l[0] : new SetObj(l))));
}
} else if (op == 'join') {
if (x is! SetObj) { throw new Error('can only join set'); }
if (y is! IntObj) { throw new Error('can only join set with int'); }
String res = '';
for (Obj obj in x.vals(interp)) {
if (obj is! IntObj) { throw new Error('joining set must contain ints'); }
res += obj.value.toString();
}
return new IntObj(int.parse(res));
}
}
}
// Unary operator (len) expression.
class Len extends Node {
final Lenop op;
final Node value;
Len(this.op, this.value);
String toString() => 'Len($op, $value)';
Obj interpret(ZincInterpreter interp) =>
op.get(interp)(interp, value.interpret(interp), null);
}
// Binary operator expression.
class Binop extends Node {
final Node lhs, rhs;
final Op op;
Binop(this.lhs, this.op, this.rhs);
String toString() => 'Binop($lhs, $op, $rhs)';
Obj interpret(ZincInterpreter interp) =>
op.get(interp)(interp, lhs.interpret(interp), rhs.interpret(interp));
}
// Clause.
enum ClauseKind { Where, Sort }
class Clause extends Node {
final ClauseKind kind;
final Node expr;
Clause(this.kind, this.expr);
String toString() => 'Clause($kind, $expr)';
Obj interpret_with(ZincInterpreter interp, SetObj set, Id id) {
List<Obj> res = [];
List<Obj> values = set.vals(interp);
switch (kind) {
case ClauseKind.Where:
for (int i=0; i<values.length; i++) {
Obj obj = values[i];
interp.push_scope();
interp.setv(id.id, obj);
interp.setv('_', new IntObj(i));
Obj x = expr.interpret(interp);
interp.pop_scope();
if (x is IntObj) {
if (x.value != 0) { res.add(obj); }
} else { throw new Error('where clause condition must be an integer'); }
}
break;
case ClauseKind.Sort:
res = values;
res.sort((x, y) {
interp.push_scope();
interp.setv(id.id, x);
Obj x_by = expr.interpret(interp);
interp.setv(id.id, y);
Obj y_by = expr.interpret(interp);
interp.pop_scope();
if (x_by is IntObj && y_by is IntObj) {
return x_by.value.compareTo(y_by.value);
} else { throw new Error('sort clause result must be an integer'); }
});
break;
}
return new SetObj(new List.from(res.reversed));
}
}
// Set comprehension.
class SetComp extends Node {
final Id id;
final Node set;
final Clause clause;
SetComp(this.id, this.set, this.clause);
String toString() => 'SetComp($id, $set, $clause)';
Obj interpret(ZincInterpreter interp) {
Obj setobj = set.interpret(interp);
if (setobj is SetObj) {
return clause.interpret_with(interp, setobj, id);
} else { throw new Error('set comprehension rhs must be set type'); }
}
}
// Operator rewrite.
class OpRewrite extends Node {
final Anyop op;
final Node value;
final Id lid, rid; // Can be null!
OpRewrite(this.op, this.value, [this.lid, this.rid]);
String toString() => 'OpRewrite($lid, $op, $rid, $value)';
Obj interpret(ZincInterpreter interp) {
if (lid != null) {
// Not bare.
op.set(interp, (interp,x,y) {
interp.push_scope();
interp.setv(lid.id, x);
if (rid == null) { assert(y == null); }
else { interp.setv(rid.id, y); }
Obj res = value.interpret(interp);
interp.pop_scope();
return res;
});
} else {
// Bare.
if (value is Magicop) {
op.set(interp, (interp,x,y) => value.interpret_with(interp, x, y));
} else {
op.set(interp, (interp,x,y) => (value as Anyop).get(interp)(x, y));
}
}
return null;
}
}
class Program extends Node {
final List<OpRewrite> rws;
final Node expr;
Program(this.rws, this.expr);
String toString() => 'Program($rws, $expr)';
Obj interpret(ZincInterpreter interp) {
rws.forEach((n) => n.interpret(interp));
return expr.interpret(interp);
}
}
// Runtime objects.
typedef Obj OpFuncType(ZincInterpreter interp, Obj x, Obj y);
class Obj {}
class IntObj extends Obj {
final int value;
IntObj(this.value);
String toString() => 'IntObj($value)';
bool operator==(Obj rhs) => rhs is IntObj && value == rhs.value;
String dump() => value.toString();
}
class SetObj extends Obj {
final List<Obj> values;
SetObj(this.values) {
if (values.length == 0) { throw new Error('set cannot be empty'); }
}
String toString() => 'SetObj($values)';
bool operator==(Obj rhs) => rhs is SetObj && values == rhs.values;
String dump() => values.map((x) => x.dump()).reduce((x,y) => x+y);
List<Obj> vals(ZincInterpreter interp) {
Obj lenobj = interp.op1['#'](interp, this, null);
int len;
if (lenobj is! IntObj) { throw new Error('# operator must return an int'); }
len = lenobj.value;
if (len < 0) { throw new Error('result of # operator must be positive'); }
return new List<Obj>.from(values.getRange(0, len));
}
}
// Parser.
class ZincParser extends LanguageParsers {
ZincParser(): super(reservedNames: ['let', 'in', 'join', 'cut']);
get start => prog().between(spaces, eof);
get comma => char(',') < spaces;
get lp => symbol('(');
get rp => symbol(')');
get lb => symbol('{');
get rb => symbol('}');
get colon => symbol(':');
get plus => symbol('+');
get minus => symbol('-');
get star => symbol('*');
get slash => symbol('/');
get eq => symbol('=');
get len => symbol('#');
get in_ => char(':');
get where => char('^');
get sort => char('\$');
prog() => reserved['let'] + oprw().sepBy(comma) + reserved['in'] + expr() ^
(_1,o,_2,x) => new Program(o,x);
oprw() => oprw1() | oprw2() | oprw3();
oprw1() => (basicop() | lenop()) + eq + (magicop() | op()) ^
(o,_,r) => new OpRewrite(o,r);
oprw2() => (id() + op() + id()).list + eq + expr() ^
(l,_,x) => new OpRewrite(l[1], x, l[0], l[2]);
oprw3() => lenop() + id() + eq + expr() ^ (o,a,_,x) => new OpRewrite(o, x, a);
magicop() => (reserved['join'] | reserved['cut']) ^ (s) => new Magicop(s);
basicop() => (plus | minus | star | slash | eq) ^ (op) => new Op(op);
op() => (basicop() + colon ^ (op,_) => new Op(op.op, true)) | basicop();
lenop() => (len + colon ^ (_1,_2) => new Lenop(true)) |
len ^ (_) => new Lenop();
expr() => setcomp() | unop() | binop() | prim();
setcomp() => lb + id() + in_ + rec(expr) + clause() + rb ^
(_1,i,_2,x,c,_3) => new SetComp(i,x,c);
clausekind() => (where ^ (_) => ClauseKind.Where) |
(sort ^ (_) => ClauseKind.Sort);
clause() => clausekind() + rec(expr) ^ (k,x) => new Clause(k,x);
unop() => lenop() + rec(expr) ^ (o,x) => new Len(o,x);
binop() => prim() + op() + rec(expr) ^ (l,o,r) => new Binop(l,o,r);
prim() => id() | intlit() | parens(rec(expr));
id() => identifier ^ (i) => new Id(i);
intlit() => intLiteral ^ (i) => new IntLiteral(i);
}
// Interpreter.
class ZincInterpreter {
Map<String, OpFuncType> op0, op1;
List<Map<String, Obj>> scopes;
ZincInterpreter() {
var beInt = (v) {
if (v is IntObj) { return v.value; }
else { throw new Error('argument to binary operator must be integer'); }
};
op0 = {
'+': (_,x,y) => new IntObj(beInt(x)+beInt(y)),
'-': (_,x,y) => new IntObj(beInt(x)-beInt(y)),
'*': (_,x,y) => new IntObj(beInt(x)*beInt(y)),
'/': (_,x,y) => new IntObj(beInt(x)/beInt(y)),
'=': (_,x,y) => new IntObj(x == y ? 1 : 0),
'#': (i,x,_2) =>
new IntObj(x is IntObj ? x.value.toString().length : x.values.length)
};
op1 = new Map<String, OpFuncType>.from(op0);
scopes = [{}];
}
void push_scope() { scopes.add({}); }
void pop_scope() { scopes.removeLast(); }
void setv(String name, Obj value) { scopes[scopes.length-1][name] = value; }
Obj getv(String name) {
for (var scope in scopes.reversed) {
if (scope[name] != null) { return scope[name]; }
}
if (name == 'S') {
var input = stdin.readLineSync() ?? '';
var list = new List.from(input.codeUnits.map((c) =>
new IntObj(int.parse(new String.fromCharCodes([c])))));
setv('S', new SetObj(list));
return getv('S');
} else throw new Error('undefined variable $name');
}
}
void main(List<String> args) {
if (args.length != 1) {
print('usage: ${Platform.script.toFilePath()} <file to run>');
return;
}
var file = new File(args[0]);
if (!file.existsSync()) {
print('cannot open ${args[0]}');
return;
}
Program root = new ZincParser().start.parse(file.readAsStringSync());
ZincInterpreter interp = new ZincInterpreter();
var res = root.interpret(interp);
print(res.dump());
}
And this goes in pubspec.yaml:
name: zinc
dependencies:
parsers: any
Intended solution
let
#x=((x=S)*(-2))+#:x,
/=cut
in {y:{x:S/0$#:x}^_=2}


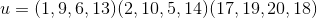
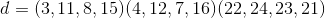




 means that
means that 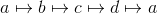












You don't explicitly state this but am I right in assuming that the cop actually has to write and post the interpreter in their answer? – Blue – 2015-10-26T14:06:33.620
@muddyfish Yes, the interpreter should be the content of the cop answer. – feersum – 2015-10-26T14:08:57.367
Can the interpreter take additional arguments? (Such as
-debug) – Loovjo – 2015-10-26T16:17:28.350@Loovjo That doesn't hurt anything, as long as it functions normally without them. – feersum – 2015-10-26T16:32:02.910
Should we try to make the language Turing-complete? – Loovjo – 2015-10-27T07:33:04.720
@Loovjo It's ok if it's not. – feersum – 2015-10-27T07:49:30.380
@feersum But should we try? – Loovjo – 2015-10-27T07:50:03.250
@Loovjo up to you. – feersum – 2015-10-27T08:14:28.713
Must it satisfy the criteria of a programming language? http://meta.codegolf.stackexchange.com/a/2073/30076
– bmarks – 2015-10-27T12:54:28.223@bmarks That's not necessary. – feersum – 2015-10-27T12:55:12.987
I don't get the
is andus in the second example output... – kirbyfan64sos – 2015-10-27T16:16:52.6871@kirbyfan64sos Output will be judged by then number of 1s printed before the program halts. Other characters are ignored. – mbomb007 – 2015-10-27T16:22:15.137
You should put a leaderboard to track how much longer an answer needs until it's safe. – kirbyfan64sos – 2015-10-28T16:19:47.987
What's so unique about 0x1936206392306? – Luminous – 2015-10-28T17:28:33.430
1
@Luminous Apparently nothing at all.
– Martin Ender – 2015-10-28T17:49:18.123Are the robber solutions required to execute in under an hour? – BMac – 2015-10-29T17:50:38.397
@BMac No. – feersum – 2015-10-29T17:53:34.917
21I nerd-sniped myself with this challenge. I created a programming language and then spent hours programming the task to see if the language could even work only to find out that it actually was unusable. – Sanchises – 2015-10-31T12:58:06.107
The cop who becomes safe with the highest score, and a positive score, wins this question. The wording suggests that votes after becoming safe do not count. Is that intentional? – Dennis – 2015-10-31T16:02:13.970
@Dennis No, it doesn't mean that. – feersum – 2015-11-01T00:22:09.630
I think it has been eight days since the last edit of this question. Looks like Dennis’ Changeling is the winner! – None – 2015-11-13T16:25:39.593
Is the input guaranteed not to contains zero (at decimal representation)? – Akangka – 2015-11-14T08:15:47.707
@ChristianIrwan
All numbers are positive integers.– feersum – 2015-11-14T08:29:58.807The interpreter must not interpret a language which was published before this challenge.Whynot – l4m2 – 2018-01-06T17:23:01.867If the solution program is too long to fit into the answer, you must post a program that generates it.Why no outlink – l4m2 – 2018-01-06T17:24:01.603