79
16
Consider a non-empty string of correctly balanced parentheses:
(()(()())()((())))(())
We can imagine that each pair of parentheses represents a ring in a collapsed telescopic construction. So let's extend the telescope:
( )( )
()( )()( ) ()
()() ( )
()
Another way to look at it is that the parentheses at depth n are moved to line n, while keeping their horizontal position.
Your task is to take such a string of balanced parentheses and produce the extended version.
You may write a program or function, taking input via STDIN (or closest equivalent), command-line argument or function parameter, and producing output via STDOUT (or closest equivalent), return value or function (out) parameter.
You may assume that the input string is valid, i.e. consists only parentheses, which are correctly balanced.
You may print trailing spaces on each line, but not any more leading spaces than necessary. In total the lines must not be longer than twice the length of the input string. You may optionally print a single trailing newline.
Examples
In addition to the above example, here are a few more test cases (input and output are separated by an empty line).
()
()
(((())))
( )
( )
( )
()
()(())((()))(())()
()( )( )( )()
() ( ) ()
()
((()())()(()(())()))
( )
( )()( )
()() ()( )()
()
Related Challenges:
- Topographic Strings, which asks you to produce what is essentially the complement of the output in this challenge.
- Code Explanation Formatter, a broad generalisation of the ideas in this challenge, posted recently by PhiNotPi. (In fact, PhiNotPi's original description of his idea was what inspired this challenge.)
Leaderboards
Huh, this got quite a lot of participation, so here is a Stack Snippet to generate both a regular leaderboard and an overview of winners by language.
To make sure that your answer shows up, please start your answer with a headline, using the following Markdown template:
# Language Name, N bytes
where N is the size of your submission. If you improve your score, you can keep old scores in the headline, by striking them through. For instance:
# Ruby, <s>104</s> <s>101</s> 96 bytes
function answersUrl(e){return"http://api.stackexchange.com/2.2/questions/"+QUESTION_ID+"/answers?page="+e+"&pagesize=100&order=desc&sort=creation&site=codegolf&filter="+ANSWER_FILTER}function getAnswers(){$.ajax({url:answersUrl(page++),method:"get",dataType:"jsonp",crossDomain:true,success:function(e){answers.push.apply(answers,e.items);if(e.has_more)getAnswers();else process()}})}function shouldHaveHeading(e){var t=false;var n=e.body_markdown.split("\n");try{t|=/^#/.test(e.body_markdown);t|=["-","="].indexOf(n[1][0])>-1;t&=LANGUAGE_REG.test(e.body_markdown)}catch(r){}return t}function shouldHaveScore(e){var t=false;try{t|=SIZE_REG.test(e.body_markdown.split("\n")[0])}catch(n){}return t}function getAuthorName(e){return e.owner.display_name}function process(){answers=answers.filter(shouldHaveScore).filter(shouldHaveHeading);answers.sort(function(e,t){var n=+(e.body_markdown.split("\n")[0].match(SIZE_REG)||[Infinity])[0],r=+(t.body_markdown.split("\n")[0].match(SIZE_REG)||[Infinity])[0];return n-r});var e={};var t=0,c=0,p=-1;answers.forEach(function(n){var r=n.body_markdown.split("\n")[0];var i=$("#answer-template").html();var s=r.match(NUMBER_REG)[0];var o=(r.match(SIZE_REG)||[0])[0];var u=r.match(LANGUAGE_REG)[1];var a=getAuthorName(n);t++;c=p==o?c:t;i=i.replace("{{PLACE}}",c+".").replace("{{NAME}}",a).replace("{{LANGUAGE}}",u).replace("{{SIZE}}",o).replace("{{LINK}}",n.share_link);i=$(i);p=o;$("#answers").append(i);e[u]=e[u]||{lang:u,user:a,size:o,link:n.share_link}});var n=[];for(var r in e)if(e.hasOwnProperty(r))n.push(e[r]);n.sort(function(e,t){if(e.lang>t.lang)return 1;if(e.lang<t.lang)return-1;return 0});for(var i=0;i<n.length;++i){var s=$("#language-template").html();var r=n[i];s=s.replace("{{LANGUAGE}}",r.lang).replace("{{NAME}}",r.user).replace("{{SIZE}}",r.size).replace("{{LINK}}",r.link);s=$(s);$("#languages").append(s)}}var QUESTION_ID=49042;var ANSWER_FILTER="!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";var answers=[],page=1;getAnswers();var SIZE_REG=/\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;var NUMBER_REG=/\d+/;var LANGUAGE_REG=/^#*\s*([^,]+)/body{text-align:left!important}#answer-list,#language-list{padding:10px;width:290px;float:left}table thead{font-weight:700}table td{padding:5px}<script src=https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js></script><link rel=stylesheet type=text/css href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b"><div id=answer-list><h2>Leaderboard</h2><table class=answer-list><thead><tr><td></td><td>Author<td>Language<td>Size<tbody id=answers></table></div><div id=language-list><h2>Winners by Language</h2><table class=language-list><thead><tr><td>Language<td>User<td>Score<tbody id=languages></table></div><table style=display:none><tbody id=answer-template><tr><td>{{PLACE}}</td><td>{{NAME}}<td>{{LANGUAGE}}<td>{{SIZE}}<td><a href={{LINK}}>Link</a></table><table style=display:none><tbody id=language-template><tr><td>{{LANGUAGE}}<td>{{NAME}}<td>{{SIZE}}<td><a href={{LINK}}>Link</a></table>
Martin Ender
Posted 2015-04-20T13:50:07.047
Reputation: 184 808















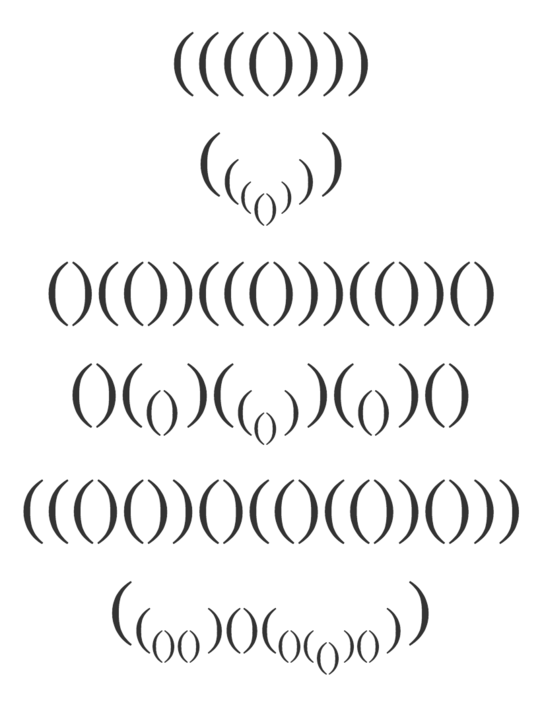




























17Alternative title: De-Lisp-ify a string. :P – Alex A. – 2015-04-20T20:25:41.303
1Are there any restrictions on the color of the output? – Matteo Italia – 2015-04-21T20:20:27.387
@MatteoItalia That's a funny question, I never considered that. In general I would probably regard the output as the byte stream of your output, not as what's displayed on screen, so a change of colour will probably indicate that you sent some additional bytes that don't really belong there. But for this question, I'm going to say the colour doesn't matter (unless it's something like black on black, obviously), and will take this to meta. – Martin Ender – 2015-04-21T20:53:02.480
1@MartinBüttner: nevermind, I found a cleaner way; let's just say that my previous idea would have shaved a byte leaving all the closed parentheses blinking blue over cyan... :-) – Matteo Italia – 2015-04-21T21:00:26.993
8@MatteoItalia oh god, I'm glad that didn't happen. ;) – Martin Ender – 2015-04-21T21:00:55.317
12@MatteoItalia: Post that version! It's worth seeing. – user2357112 supports Monica – 2015-04-22T04:28:45.550
@user2357112: that would be the 30 bytes version, but with the first
push/poprestored to the originalmov ax,0b8c3h/mov es,axand thelodswrestored tolodsb. IIRC that was 33 bytes, I discarded that possibility because changing themov/movwith apush/popalready produced that gain without the blinking; however then I resorted to some similar trick to shave some other bytes, so we are back to ugly colors (but no blinking:-(). – Matteo Italia – 2015-04-22T11:41:31.853If I had this idea on my Math exams, it would be so cool, for not making mistakes... – sergiol – 2017-07-06T22:48:57.510